

Elixir和Phoenix是2022年Web应用程序的绝佳选择
- admin
- 13 Dec 2023
如何在 2022 年为应用选择最佳的 Web 编程语言和框架?这是可能吗?我相信是的,在这篇博文中,我将尝试说服您为什么 Elixir 和 Phoenix 是您正在寻找的完美组合。 ## Elixir: 生产力等于更少的成本 生产力仍然是编程语言的一个被大大低估的特性。一般来说,市场上的大多数应用程序都必须实现一些业务目标,众所周知,我们产生的成本越少
Read More上周末,在使用 Elixir 参加 "十亿条记录挑战"(The One Billion Record Challenge,1BRC)时,我学到了很多东西。我想与大家分享所有这些东西,但也许这最适合在演讲中分享。因此,在这篇文章中,我将只关注其中的一点:读取包含数百万条记录的巨大文本文件的性能。
我的 1BRC 解决方案的总体结构是这样的:
path
|> File.stream!() # Streams the lines of the file
|> Stream.chunk_every(@chunk_size) # Creates chunks of lines for processing
|> Enum.map(&Task.async(fn -> process_chunk(&1) end)) # Creates a task for each chunk
|> Enum.map(&Task.await(&1)) # Waits for each task to finish
|> Enum.reduce(%{}, &summarize_chunk_results/2) # Merges the results of all tasks
|> Enum.map(&stats/1) # Calculates the stats for each weather station在本文中,我们假设 @chunk_size 的值为 100_000。
为了优化性能,我对最初的(非常幼稚的)解决方案进行了多次迭代,但结果与我在 Javaland 中看到的结果相差甚远(当时约为 8 秒)。
然后,我使用 fprof、erlgrind 和 qcachegrind 对代码进行了剖析(请参阅此处的基本说明),根据对结果的分析,我设法做出了一些相当不错的改进。这个过程我重复了几次,但最后我发现很多时间都花在了与流相关的操作上,这让我很恼火。
我怀疑仅仅读取文件就耗费了大量时间,事实也确实如此!下面是一张树形图,显示了我向程序输入 1000 万行数据时执行时间的分布情况。
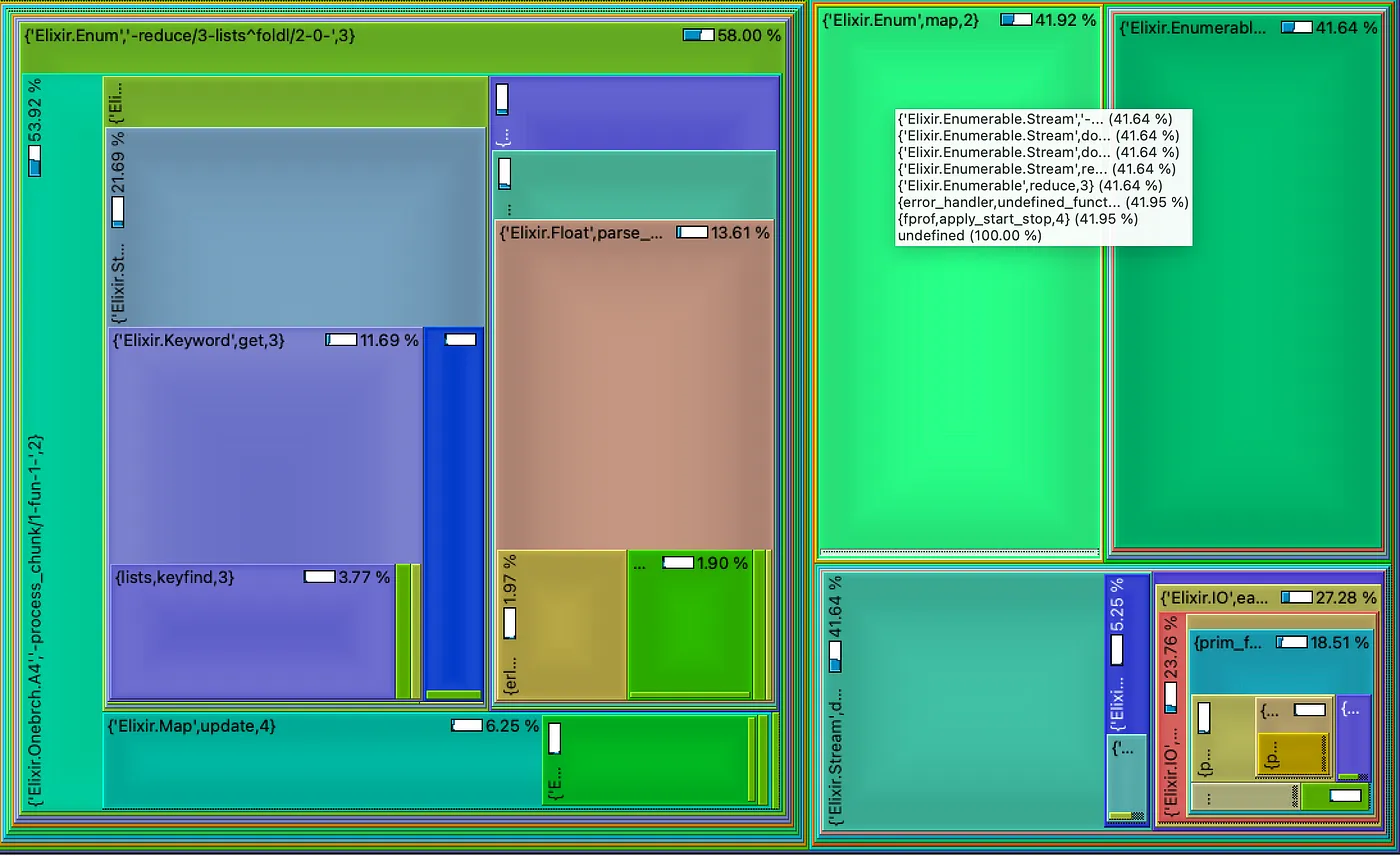
右边的大矩形由 Enumerable.Stream 模块中的函数和 Enum.map/2 的调用组成。
让我们仔细想想:当我们调用 Enum.map/2(第 4 行)时,每次迭代都会向 Stream.chunk/2 生成的流请求新的行块。由于流是lazy地评估的,因此该流会向 File.stream!/1 生成的流请求足够多的行来填充一个块(或文件的最后一行,如果没有了)。这就是为什么 Enum.map/2 似乎要花费大量时间的原因。
但是......读取文件花费的时间几乎占总时间的一半!这可不好!一点都不好
在家里的办公室转了一会儿圈后,我输入了一个小程序来确认我的发现,并将其作为不同读取文件方法的基准。
path
|> File.stream!()
|> Stream.chunk_every(@chunk_size)
|> Enum.map(fn _ -> :ok end)我们的想法是测量读取文件和创建大段行所需的时间。
哦!在我们深入研究结果之前,我使用的机器是 MacBook Pro,配备苹果 M1 Max 芯片(10 个内核)和 32 Gb 内存。
那么,我们开始吧...
| # records | size | time (sec) |
| ---------- | ------ |----------- |
| 1 M | 13 Mb | 0.19 |
| 10 M | 132 Mb | 1.58 |
| 100 M | 1.3 Gb | 15.47 |
| 1 B | 13 Gb | 156.39 |这太疯狂了!你不觉得吗?在这种情况下,我根本无法与 Java 解决方案相提并论!**仅仅读取一个 10 亿条记录的文件,我就要花 156 秒!**我必须承认,此时我感到非常失望和沮丧。我该怎么办呢?

然后我又想:在不使用流媒体的情况下读取整个文件需要多少钱?结果发现,对于 10 亿条记录的文件(13 Gb),答案是....🥁🥁🥁
iex(1)> Benchmark.measure(fn -> File.read!("measurements_1_000_000_000.txt") end)
4.87 secs 有时需要更长的时间,但无论如何,也就 5 秒左右!那么,为什么以流式方式读取并创建 10_000 个数据块需要 156 秒?
于是我开始思考读取文件并从中汲取行数的不同方法。最后,我发现了其他 4 种不同的方法(在 Elixir 论坛的帮助下)。下面我将逐一向大家介绍,然后再向大家展示我的基准测试结果。
这是最原始的方法。让我们给它起个代号:fstream。
这意味着基本上要在 File.read!/1 返回的巨大二进制文件中创建一个行流。 由于我从未创建过行流,所以花了好长时间才成功实现。这种方法的代号是 :whole_read。
def lines_stream(path, :whole_read) do
path |> File.read!() |> line_stream()
end
def line_stream(b) when is_binary(b) do
Stream.unfold(b, fn b ->
case String.split(b, "
", parts: 2) do
[line, rest] ->
{line, rest}
[""] ->
nil
end
end)
end在这种方法中,读取整个文件后,我们将整个二进制文件作为源文件创建一个 Erlang IO 设备,然后从中创建行流。我在论坛上发现了这种方法。代码名是 :whole_read_string_io。
def lines_stream(path, :whole_read_string_io) do
{:ok, io_dev} = path |> File.read!() |> StringIO.open()
IO.binstream(io_dev, :line)
end那么,如果我们以大块(二进制模式)读取文件,并从中通过一个新的数据流产生行呢?这基本上就是每次读取 500_000 字节的数据块,然后从每个数据块中创建一个行列表,并将其输入到一个行流中。代码名为 :chunked_bin_read。
def lines_stream(path, :chunked_bin_read) do
path |> File.stream!([], 500_000) |> line_stream_from_binary_stream()
end
def line_stream_from_binary_stream(bin_stream) do
bin_stream
|> Stream.transform("", fn chunk, acc ->
[last_line | lines] =
acc <> chunk
|> String.split("
")
|> Enum.reverse()
{Enum.reverse(lines), last_line} # reverse is only needed if you care about original order of the lines
end)
end这与方案 4 类似,但我们不依赖 File.stream/3,而是一步读取整个文件。然后,我们创建一个读取大块二进制文件的流,再创建一个读取行的流。代码名为 :whole_read_chunked_bin。
def lines_stream(path, :whole_read_chunked_bin) do
path |> File.read!() |> binary_stream() |> line_stream_from_binary_stream()
end
def binary_stream(b, chunk_size \ 500_000) when is_binary(b) do
Stream.unfold(0, fn skip ->
case b do
<<_skipped::binary-size(skip), chunk::binary-size(chunk_size), _rest::binary>> ->
{chunk, skip + chunk_size}
<<_skipped::binary-size(skip)>> ->
nil
<<_skipped::binary-size(skip), chunk::binary>> ->
{chunk, skip + byte_size(chunk)}
end
end)
end
def line_stream_from_binary_stream(bin_stream) do
# defined above
end长话短说,这是我在改变输入大小(最多 10 亿条记录)的情况下,每种方法得到的结果:
| size | fstream | whole_read_string_io | whole_read | chunked_bin_read | whole_read_chunked_bin |
| ----- | ------- | -------------------- | ---------- | ---------------- | ---------------------- |
| 1 M | 0.19 | 1.12 | 0.32 | 0.12 | 0.16 |
| 10 M | 1.54 | 10.90 | 2.76 | 0.87 | 1.09 |
| 100 M | 15.28 | 110.36 | 26.97 | 8.44 | 10.61 |
| 1 B | 152.69 | 1154.50 | 269.84 | 85.81 | 111.95 |可以看出,chunked_bin_read 是时间最短的解决方案。
这种方法的原理是,在使用 Enum.map(fn _ -> :ok end) 进行迭代时,每次迭代都会向输入的流请求一个字符串块,然后这个流会向 File.stream!([], 500_000) 返回的流请求下一个元素,结果是一个 500_000 字节的二进制元素,然后我们就会生成尽可能多的文本行。这样,通过一次 IO 读取操作,我们就能为一个数据块创建大量行。这就是所谓的缓冲读取。

等等,有没有一种方法可以使用现有的标准库来实现这一功能,而不需要进行复杂的流操作?
很遗憾没有。File.stream/3 的文档指出
The
line_or_bytesargument configures how the file is read when streaming, by:line(default) or by a given number of bytes. When using the:lineoption, CRLF line breaks ("\r\n") are normalized to LF ("\n").
也就是说,你可以按行或按字节块读取数据。根本不存在 "请给我读几行,但要以缓冲方式从设备读取 "这样的说法。阅读 File.stream/3 的实现后,我证实了这一点。
至于这是否是一个缺失的功能,我们可以在正式版本中讨论,但回顾我刚才展示的基准测试,拥有这一功能岂不是非常有益?在我的使用案例中,执行时间几乎缩短了一倍。
我的最终解决方案的执行时间分布如树形图所示。
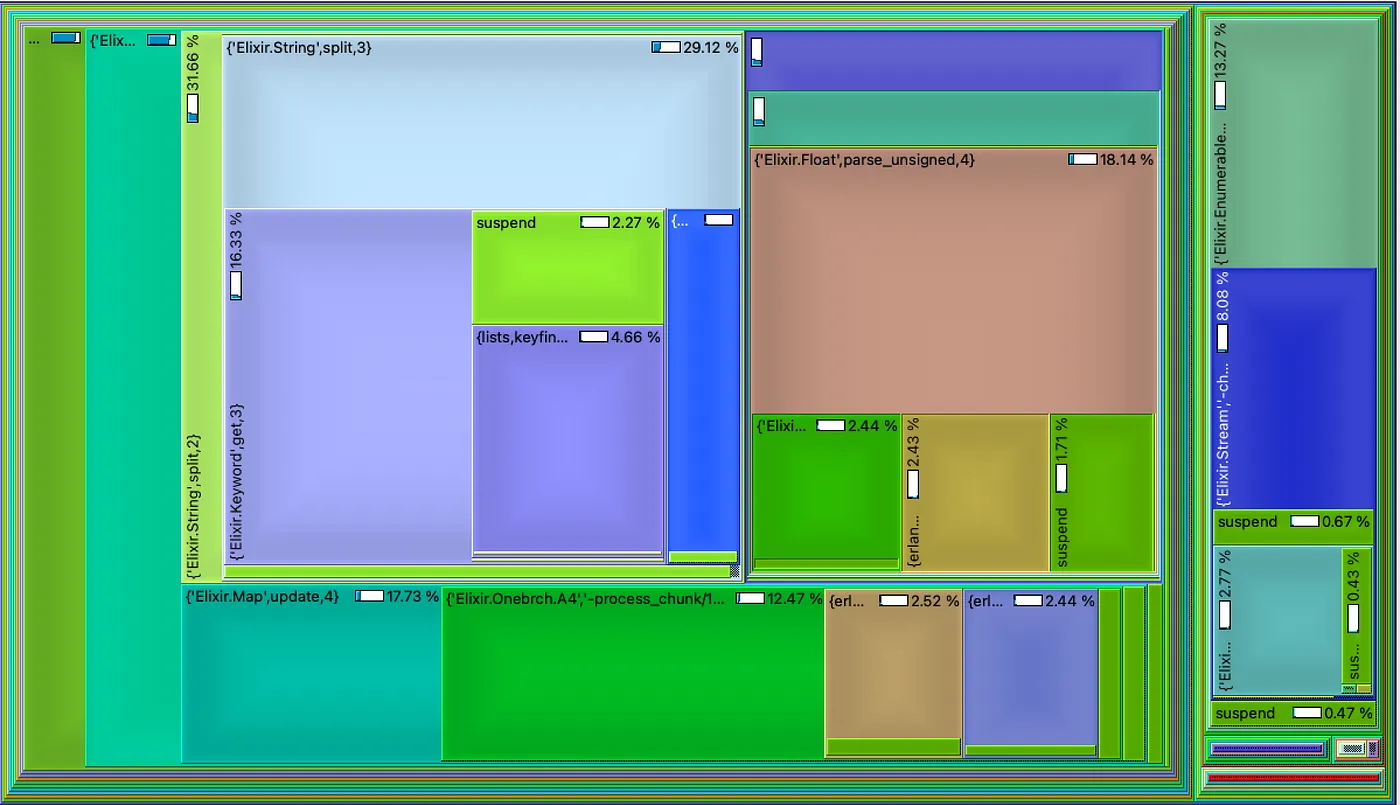
右边的大矩形代表读取文件所花费的时间(约 14%),在我看来仍然很大,但这是我能得到的最好结果。
你可以看到中间顶部有两个大矩形。它们与 String.split/2 和 Float.parse/1 函数有关,我使用这两个函数来处理每条记录。我猜有一种更理想的方法,但我还没有在 Erlang/Elixir 中找到。
总之,仅仅读取文件中的记录(参见上面的基准测试)就需要 85 秒,这与某些人用 Java 编写的解决方案(尽管这些基准测试是在 64 核机器上进行的)🤷🏽️。
收获
就到这里吧
欢迎提出任何意见或建议!
如何在 2022 年为应用选择最佳的 Web 编程语言和框架?这是可能吗?我相信是的,在这篇博文中,我将尝试说服您为什么 Elixir 和 Phoenix 是您正在寻找的完美组合。 ## Elixir: 生产力等于更少的成本 生产力仍然是编程语言的一个被大大低估的特性。一般来说,市场上的大多数应用程序都必须实现一些业务目标,众所周知,我们产生的成本越少
Read More我开始使用 Elixir 大约有一年了。起初,我只打算在博客中使用这种语言,认为它可以帮助我更好地说明 Erlang 虚拟机(EVM)的优势。然而,我立即被这种语言所带来的魅力所吸引,并很快将其引入了我当时正在开发的基于 Erlang 的生产系统。如今,我认为 Elixir 是开发 EVM 支持系统的更好选择,在这篇文章中,我将尝试强调它的一些优点,并消除对
Read MoreErlang 是一种受信任且稳定的语言,用于在主要系统中运行核心程序,由 Ericsson 发明。Erlang(和 Elixir)被许多领域的许多行业使用,包括金融科技、安全、区块链和物联网。 公司之所以选择 Erlang 和 Elixir,是因为可以轻松编写可部署在分布式网络中的容错和可扩展程序。Erlang 和 Elixir 都是函数式语言,它们可以使
Read More
